大數據和AI 在塑料行業的可能性
2021-09-03 來源出處:uni software plus CEO Michael Aichinger

通過數位化、工業4.0、大數據、人工智慧和機器自我學習等關鍵詞。不可否認數位世界提供巨大的潛力和價值。而另一方面,對於數位化項目的實施成本,以及投資回報率問題,大家尚未清楚瞭解。不過,在這個充滿危機和盈利壓力越來越大的時代,數位化讓我們能夠樂觀的看待行業的未來和機遇,特別是塑料行業。
建立大數據架構或人工智慧應用開發的過程中,從始至終都會面臨有關效率、品質、穩定性或可靠性的問題:
- 減少殘次品?
- 減少停機時間?
- 如何擴大工藝窗口,從而提高工藝穩定性?及這些問題引出的其他問題:
- 哪些工藝參數影響我的產品品質?
- 工藝是否穩定,以及工藝窗口是否有效?
- 機器的部件是否有磨損的跡象?
- 原材料的變化和波動會對最終產品產生什麽影響?
第一步是「分析問題」,對於跨學科團隊合作來說,這是最有效的方式。數據分析團隊中的機械工程師、控制工程師、工藝工程師和應用工程師與數據分析師,可以採不同方式與從不同角度來看待存在的問題。當我們澄清了所有與工藝檢查有關的問題(檢查什麽?如何檢查?以什麽頻率進行檢查?),我們即已實現了第一個目標。
當專家團隊認為那些重要的數據能夠被收集和保存時,意味著我們已經到達另一個里程碑。此外,數據被賦予語義,得到驗證,最好是不僅存儲了原始數據,且數據已經在數據模型中「準備好了」以供調用分析。這一點上,我們有意省略了數據量的問題。大數據場景可能會以不同的方式出現,有可能是由於需要同時進行很多不同參數的測量和收集,或由於需要存儲來自於多臺機器的數據用於比較分析,或可能是某一個問題需要記錄很長一段時間的數據(預測性維護保養是常見的例子)。
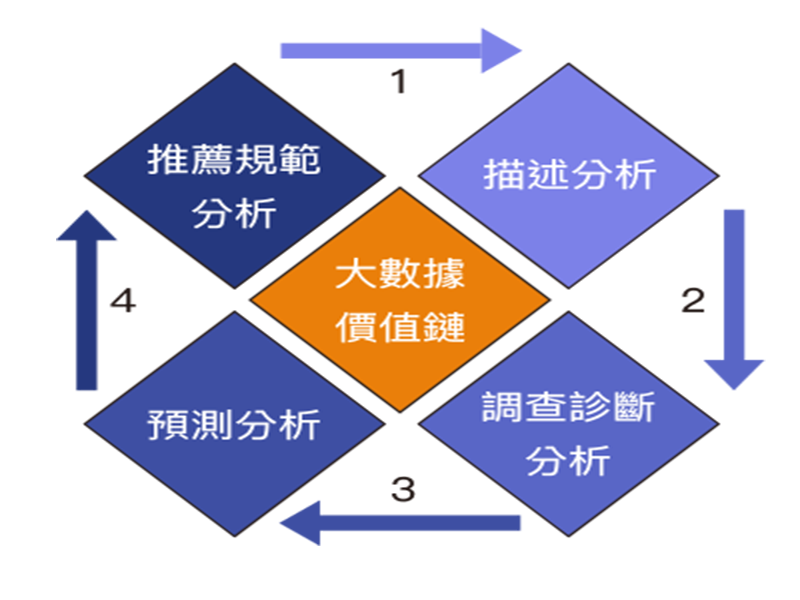
IT 架構的要求
IT 架構的要求要類似上述的方式應用大數據價值鏈,必須採取以下步驟:
- 理解問題;
- 數據收集;
- 數據分析和問題建模;
- 開發解決方案;
- 實施解決方案.
先不考慮操作維度和解決方案安全性的問題,而將重點放在功能和所需的軟體層面上。
為了採集數據,我們要有相應機器的驅動。這些數據通常是沒有元信息的,我們必須對其進行修飾(提供語義)。由於機器種類繁多,這將是個非常耗費時間的過程。數據採集進來之後,我們要解決數據路由和存儲的問題。數據是否要保存到本地系統中?是否要在雲端備份?是否要分配至多個端點?哪裡分析數據最好?是否可以通過數據聚合來節省成本?在處理數據的過程中,必須明確初始分析(這是發現問題和開發解決方案所必須的)、利用現有算法進行週期性分析(批處理)和利用現有算法進行連續分析(流分析)之間的區別。例如,設備每天自動測量一次磨損,我們在每日運行的批處理作業中對此進行分析,以監測磨損程度。拿射出機來說,我們要對每個射出週期進行穩定性分析,而對於押出機,我們則要對測量的變量進行連續性分析——這是流分析的典型例子。一般來說,分析的頻率越高,就能夠越接近那個點,進行有效的人為介入。分析的結果可以指導我們人為介入干預控制系統,這使得分析系統和控制系統之間的界限變得模糊了。
顯然,數位化帶來的大量應用場景和機遇也需要靈活的實施架構。一般來說,數據分析/ 大數據(混合系統也具有優勢)應該優先考慮既可以「本地安裝」又可以在雲端實施的靈活架構。原則上,通過各種層來描述的架構比較常見,屬於普遍的大數據架構,比如Lambda 架構。組成這種架構的單個組件可以用於邊緣計算/ 霧區。
接口層負責數據接口以及與解决方案的自身模塊和第三方系統的所有通信。數據管道用於處理數據流。它的特點是可伸縮性和複製能力,以及由此帶來的故障安全特性。存儲層既是數據池,又是數據樞紐,即不僅存儲轉換後的數據,也存儲原始數據。
最關鍵的是「收穫低垂的果實」
要成功實施數據分析和人工智慧領域的項目,需要成熟的理念和經驗豐富的合作夥伴。最關鍵的是要從簡單的問題開始,從而「收穫低垂的果實」。在項目實施過程中,我們要從大數據價值鏈的技術和分析層面逐步建立所需的基礎架構和能力,從而解決更複雜的問題。